Architecture de TRex
Cette figure montre une vue générale du système développé : Architecture de l’applicaiton
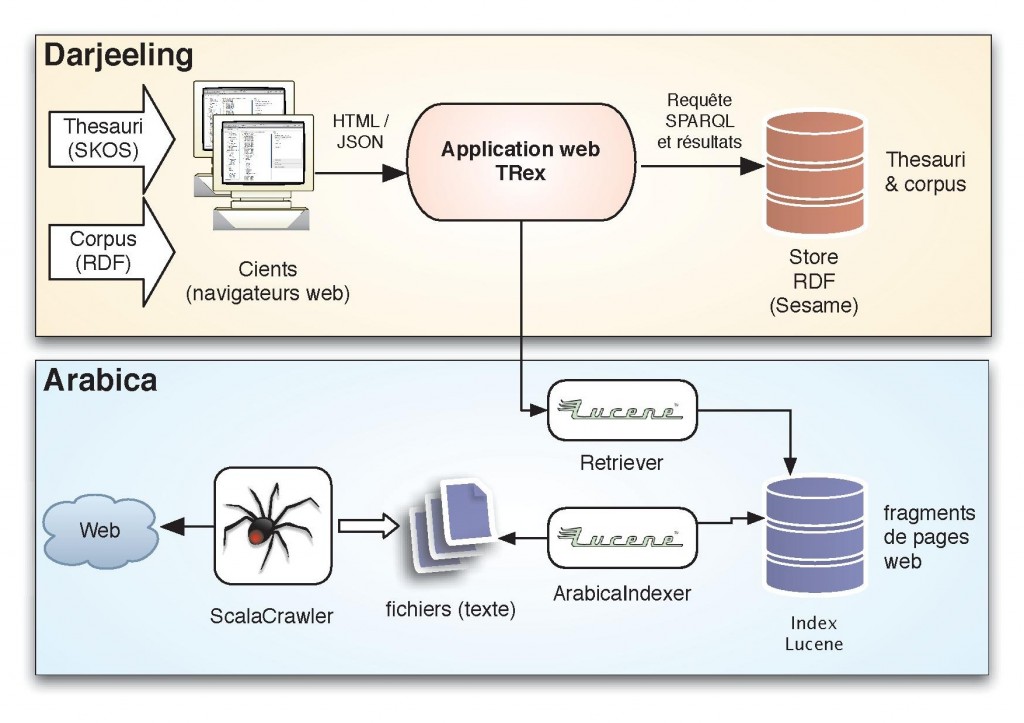
Le projet Darjeeling constitue l’application web principale : les utilisateurs interagissent avec l’application au moyen d’interfaces web (au sein d’un navigateur courant). Ils peuvent ainsi naviguer au sein des thesauri, effectuer des recherches et des analyses. Ils peuvent également insérer des thesauri et des représentations du/des corpus indexé(s) . Ces interactions se font de manière standard, en utilisant le protocole HTTP pour véhiculer des pages web (HTML) et des données (JSON) de manière asynchrone (AJAX). L’application utilise un Store RDF, qui peut être apparenté à une base de données. Celui-ci stocke les thesauri et les corpus associés . Actuellement, nous utilisons un serveur Sesame.
L’application web centrale est chargée des principaux traitements : analyse et stockage des thesauri, gestion des données associées, production de vues, recherche, … On notera encore que l’application Darjeeling peut effectuer une recherche de cooccurrence d’utilisation des concepts dans le corpus des documents indexé, dans le but de découvrir de nouvelles relations d’apparentement ou de spécialisation / généralisation entre concepts du thésaurus. Ce processus est semi-automatique : l’application n’enregistrera ces relations de manière permanente que si l’utilisateur les a validé.
L’application peut également utiliser des données externes, notamment afin d’établir de nouvelles relations entre les concepts d’un thésaurus. Pour ce faire, l’application utilise des données indexées à l’aide de Lucene : il s’agit d’un projet open source écrit en Java, qui jouit d’une très bonne réputation, et permet l’indexation et la recherche de documents variés de manière très efficace.
Le projet Arabica vise justement la création d’un tel set de données indexées. Dans un premier temps, le ScalaCrawler effectue une navigation automatique du web, et récolte des fragments de page, qu’il sauvegarde sous forme de fichiers texte. Il s’agit d’une application autonome, en ligne de commande. Il serait toutefois aisé de créer une interface graphique pour en faire une application plus conviviale, ou de l’intégrer au sein de l’application web. Ceux-ci peuvent alors être indexés par l’application ArabicaIndexer, qui créera un index Lucene. Celui-ci se présente sous la forme d’un simple dossier. Un Retriever permet l’exploitation de cet index, en permettant la recherche de termes, et en retournant un ensemble de données issues de l’index, sous forme de structure de données en RAM. Ce retriever peut être utilisé par l’application web principale, ou pour toute autre utilisation ultérieure.
Le projet Arabica est utilisé par Darjeeling : il permet d’extraire les documents qui contiennent un terme donné, et les concepts présents dans ces documents. L’application Darjeeling peut alors opérer une analyse de cooccurrence pour déterminer les utilisations conjointes de concepts, et proposer alors des relations entre concepts du thésaurus, ou de concepts à ajouter.